인공지능(artificial intelligence, AI)은 인간의 지능(학습 능력과 추론 능력, 지각 능력, 자연 언어의 이해력 등)을 컴퓨터 프로그램으로 구현하는 기술로서, 분야별로 보면 지식 표현, 문제 해결, 지식시스템, 자연어 처리, 학습, 인지모델, 지능로봇 등으로 구분할 수 있다.
인공지능 시스템은 세 가지 기능을 할 수 있어야 하는데 첫째는 지식(컴퓨터 입장에서는 데이터)을 기호체계를 이용해서 저장할 수 있어야 하며, 둘째는 이러한 지식을 추론 (reasoning) 과정을 통해 문제 해결에 적용할 수 있어야 하고, 셋째는 실험을 통해 얻은 새로운 지식을 수용하여 학습할 수 있어야 한다.
로봇 지능 소프트웨어의 핵심인 인공지능은 궁극적으로 사람과 유사한 수준으로 판단하고 행동하는 능력을 갖추어야 하는데, 이에 해당하는 인공지능 시스템은 최근 연구가 활발하게 진행되고 있는 인지 에이전트(cognitive agent)와 심층신경망(deep neural network), 강화학습(reinforcement learning), 최적화 알고리즘(optimization method)이다.
1. 인지 에이전트
인지 아키텍처(cognitive architecture)는 메모리, 프로그램 실행과 제어 컴포넌트, 데이터 표현, 입출력 장치들로 구성된 컴퓨터 아키텍처 구조 위에 환경과 태스크에 대한 지식의 표현과 습득, 활용을 지원하며, 목표 기반 동작을 통해 주어진 목표를 달성할 수 있게 한다. 이 과정을 공식으로 표현하면 “아키텍처+지식=행위”가 된다.
인지 아키텍처에서 코딩되는 지식은 일반지식(general knowledge)과 태스크지식(task
knowledge)을 포함하는데, 일반지식은 언어처리, 계획, 회고적 추론(retrospective reasoning) 등 일반적인 인지 능력을 뒷받침하는 지식을, 태스크지식은 문제와 기술 영역 (domain)에 국한된 지식을 각각 의미한다.
인지 아키텍처는 지능시스템에 요구되는 주요 기능인 지각(perception), 추론(reasoning), 계획(planning), 언어처리(language processing), 학습(learning)을 잘 조정하는 역할을 수행 해야 한다.
인지 아키텍처는 동적인 환경에서 태스크들을 잘 수행하도록 지식을 학습, 코딩, 활용하는 것을 지원하는 구조를 갖추고 있어야 하며, 의사 결정과 환경과의 상호작용 또한 지원해야 한다.
인지적 에이전트 아키텍처로는 Soar, ACT-R, LIDA, Clarion, EPIC, Icarus 등이 발표되었다.
이 중에서 Soar는 인간처럼 임의의 환경에서도 학습과 경험으로 얻게 된 지식을 저장하 고, 불러오며, 처리함으로써 다양한 방식으로 작업을 수행하고 문제를 풀 수 있는 인간 수준 AGI(artificial general intelligence)를 목표로 1981년부터 ALLEN NEWELL, HERBERT SIMON, JOHN LAIRD에 의해 공동으로 개발된 인지적 에이전트이다(LAIRD, 2006).
Soar는 MICHIGAN대학교 JOHN LAIRD 교수의 주도로 현재 9.6버전이 매뉴얼과 다양한 예제와 함께 전용 웹사이트에 오픈소스로 공개되어 있다.
(1) Soar(state, operator, and result)
Soar는 지식집약적 추론(knowledge-intensive reasoning)과 반응적 실행(reactive execution), 계층적 추론(hierarchical reasoning)과 계획(planning), 학습(learning) 등이 통합되어 있는 범용 인지 아키텍처다.
Soar는 주어진 문제와 하위문제(subproblem)에 대해 광범위한 종류의 타입과 레벨을 사용할 수 있어서, 미리 작성되었거나 경험을 통해 새로 학습된 사용가능 지식을 동적 으로 융합하여 잘 동작할 수 있다.
Soar의 구성 요소는 다음과 같다.
• 복수개의 장기기억(long-term memory) 시스템: 절차적(procedural)·삽화적(episodic)
·의미적(semantic) 메모리 • 복수개의 단기지식(short-term knowledge): 작업 메모리 요소(working memory element), 상징적(symbolic)・도식적 (diagrammatic)・형상기반(imagery-based) 표현 • 복수개의 학습 메커니즘: 강화학습(reinforcement learning), 청킹(chunking), 삽화적· 의미적 학습
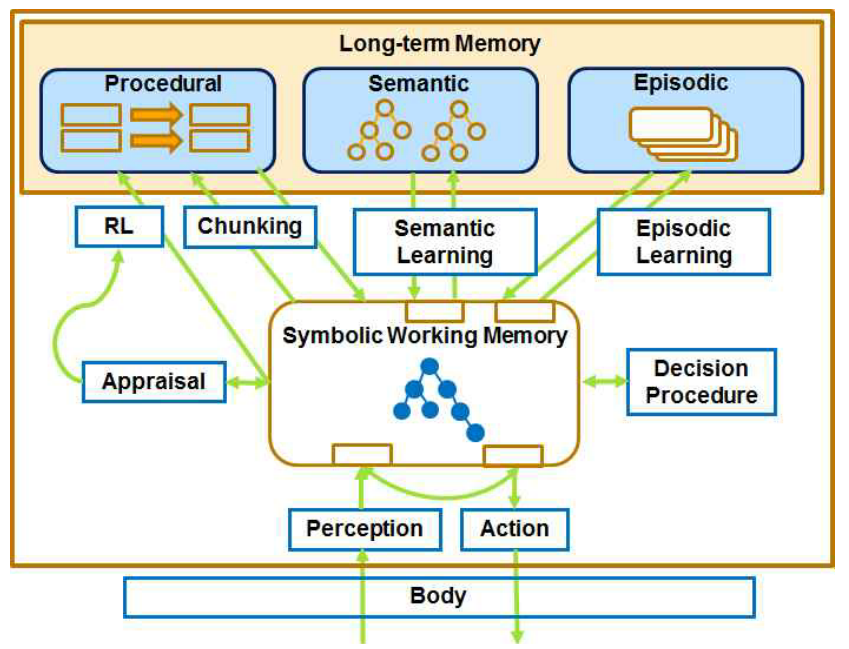
Soar의 작업 메모리 요소는 Soar 에이전트의 외부환경(world)과 내부 추론(reasoning)에 관한 모든 동적인 정보, 즉 센서 데이터, 중간 계산값, 현재 연산자, 그리고 목표(goal) 등을 담고 있다. 작업 메모리 요소는 노드와 링크를 이용하여 식별자(identifier)-속성 (attribute)-값(value)의 삼중구조로 구성되어 있다. 식별자는 자신으로부터 링크가 나오는 노드이며 속성을 가질 수 있다. 속성은 작업메모리의 특성(색, 크기, 무게)을 나타내 며, 값은 속성이 가리키는 노드를 의미한다.
작업 메모리 요소의 객체(object)는 동일한 식별자를 공유하는 작업 메모리 요소들의 집합을 의미하며, 블록, 벽, 음식조각, 보드 위에 있는 셀 등의 실세계와 관련된 것들을 표현한다. [그림 2-2]는 작업메모리의 예로서 “테이블 위에 두 개의 블록이 있는 데, 하나는 다른 하나 위에 있고, 하나는 테이블 위에 있다.”는 상황을 표현한다.

[그림 2-3]은 Soar의 결정 사이클(decision cycle)을 나타낸 것으로, 전체적으로 연산자 선택(operator selection)과 연산자 적용(operator application)으로 구분할 수 있다.
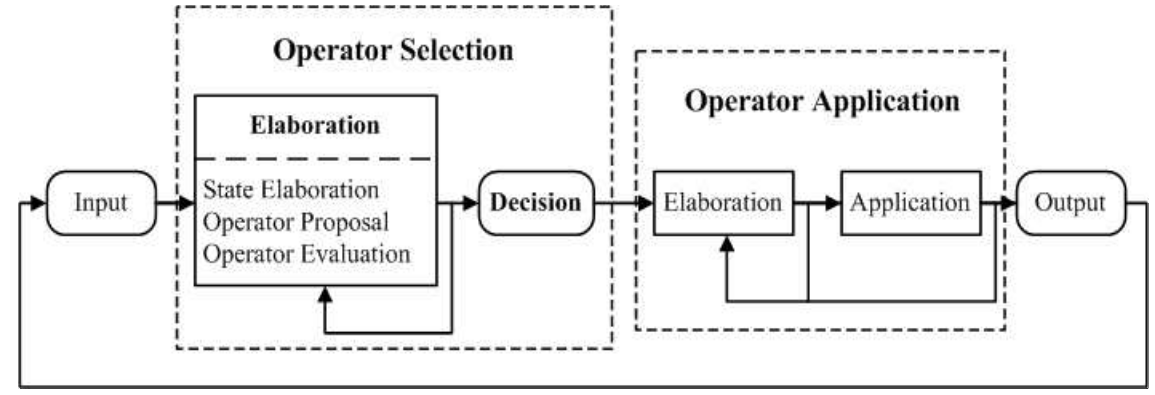
연산자 선택에는 상태 정교화(state elaboration), 연산자 제안(operator proposal), 연산자 평가(operator evaluation)의 세부 단계가 있고, 연산자 적용에는 연산자 정교화 (operator elaboration)와 연산자 적용(operator application)의 세부 단계가 있다.
상태정교화란 다른 작업 메모리 요소의 조합을 추상화한 것을 생성하고, 상태 공간에서 이를 새로운 증가물(augmentation)로 표현하는 작업을 의미한다. 상태정교화 규칙은 상태에서 복수개의 작업 메모리 요소 구조를 생성하며 병렬로 발화하는 복수개의 인스턴스들을 가질 수 있는데, 만약 어떤 작업 메모리 요소 구조가 현재 상태를 변화시 키지 못하면 철회(retraction)되어서 모두 제거된다.
Soar 연산자의 선호도(preference)에는 acceptable, reject, better/worse, best, worst, indifferent 등의 기호 선호도와 0에서 1까지의 수치적 선호도가 있으며, 결정(decision) 단계에서 연산자 후보들의 선호도에 기반하여 하나의 연산자를 선택한다. 기본적으로 연산자는 Soar가 현재의 상태로 테스트 한 후 acceptable 선호도를 얻어야 제안 (propose)되는데 연산자제안은 그 연산자의 이름과 파라미터 등을 선언하는 데 필요한 추가적인 작업 메모리 요소를 생성한다. 이렇게 후보 연산자가 제안되면 다른 연산자와 우선순위를 비교해서 선호도를 생성하는데 이 과정이 연산자평가이다.
이때 현재 연산자를 포함하는 작업 메모리 요소의 구조가 변화되는데, 만약 불충분하 거나 충돌하는 선호도를 가진 연산자가 있다면 Soar는 교착상태(impasse)를 발생시키고 하위상태(substate)를 생성한다. 이 교착상태는 이후에 추가된 하위상태의 선호도에 의해 해소될 수 있으며, 청킹(chunking)은 이렇게 만들어진 규칙을 교착상태와 교체하여 새로운 규칙을 만든다.
연산자적용 시 연산자가 선택되었는지를 테스트하고 그 후 연산자에 추가적인 구조를 생성하여 관련된 파라미터를 연결함으로써 연산자적용을 준비하는 연산자정교화와, 그
결과로서 상태에 지속적인 변화를 가하며 내부적 혹은 외부적 행위를 일으키는 연산 자적용 단계가 있다. 이 단계가 완성되면 출력(output)단에서 그 명령을 실행하고, 그결과로서 환경 인식이 변화하면 이후의 연산자선택 단계에서 현재 연산자가 철회되고 새로운 연산자가 선택될 것이며 이 과정은 계속 반복된다.
Soar에 대한 보다 상세한 내용은 http://soar.eecs.umich.edu/downloads/Documentation/ SoarManual.pdf에 접속해서 매뉴얼을 다운로드하면 매뉴얼 안에 잘 설명되어 있다.
2. 심층신경망
심층신경망(deep neural network, DNN)은 인공신경망(artificial neural network)을 확장한 것이다. 인공신경망은 인간의 뇌를 기반으로 한 추론모델이며, 인간의 뇌는 약 1,000억개의 신경세포(neuron)와 각 뉴런을 연결하는 6조개의 시냅스(synapse)로 구성되어 있다. 각각의 뉴런은 [그림 2-4]처럼 신경세포체(soma), 수상돌기(dendrite), 축색돌기(axon), 축색종 말(axon terminal)로 구성되어 있다.

인간은 새로운 내용을 학습할 때 뇌에 있는 신경세포(뉴런)들이 축삭돌기를 뻗어 인접한 뉴런의 수상돌기에 접근함으로써 연접 부위인 시냅스를 형성한 후 전기적 신호를 전달하 고, 동일한 학습을 반복하면 이 연결 강도가 더욱 강해져서 오랜 시간이 지나도 그 내용을 다시 기억해 낼 수 있다.
이러한 신경생리학적 과정을 수학적으로 가장 간단하게 모사한 신경망(neural network)이 1958년 로젠블래트(ROSENBLATT)가 발표한 단층 퍼셉트론(perceptron)이다. 단층 퍼셉트 론은 [그림 2-5]처럼 입력층과 뉴런/노드, 출력층으로만 구성되어 있으며, 입력값이 어느 영역에 속하는지 분류하는 목적으로 개발되었다.

뉴런/노드는 입력 신호의 가중치 합을 계산하여 임계값 이상이 되면 계단 함수나 시그 모이드(sigmoid) 함수 같은 활성화 함수(activation function)를 출력신호로 보낸다. 시그모 이드 함수를 활성화 함수로 쓴 경우를 식으로 표현하면 다음과 같다.
$y=f\left ( X= \sum_{i=1}^{n}x^{_{i}}w^{_{i}}-\theta \right )=\frac{1}{1+e^{-X}} \hspace{20em} (1)$
1962년 로젠블래트는 센서(sensor) 유닛, 연계(association) 유닛, 반응(response) 유닛의 3개 유닛으로 확장 구성된 퍼셉트론 이론을 발표했는데, 이를 다층 퍼셉트론(Multi-Layer Perceptron)이라고 한다. 이는 입력층(input layer), 은닉층(hidden layer), 출력층(output layer)으로 구성된 피드포워드 신경망(feedforward neural network)이라고도 불리며, DNN의 기본구조를 이룬다. [그림 2-6]은 2개의 은닉층이 있는 다층 피드포워드 신경망을 보인다.
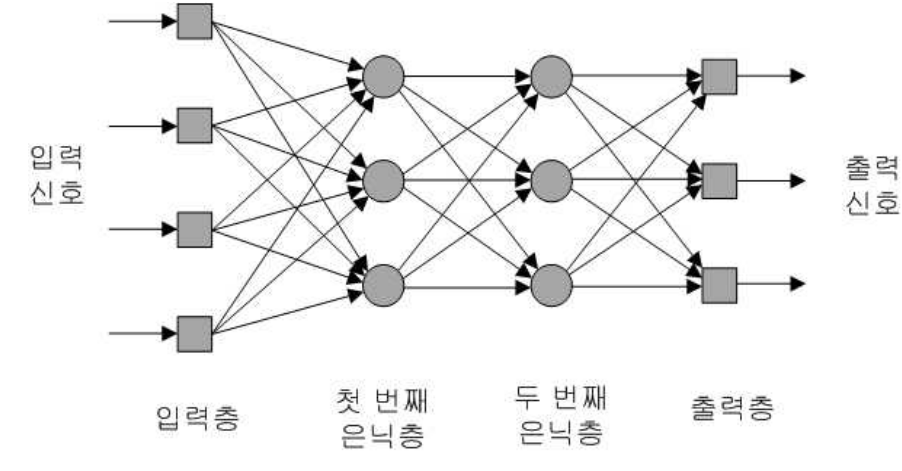
피드포워드 신경망에서 입력층은 입력 데이터를 받아들이는 기능을 하며, 입력층의 노드 (뉴런에 대응) 개수는 입력 데이터의 특성값의 개수와 동일하다.
피드포워드 신경망 은닉층에 있는 노드는 두 가지 역할을 하는데, 첫 번째는 앞 층에서
전달받은 데이터를 가중치를 고려해 선형적으로 합산하고 식 (1)의 활성화 함수(activation function)로 계산한 값을 다음 층의 뉴런으로 전달한다. 은닉층은 여러 층이 될 수 있으며, 노드 수가 너무 많으면 오버피팅(overfitting)이 발생할 수 있고 너무 적으면 입력 데이터를 충분히 표현하지 못할 수 있으므로 적절한 개수를 정해야 한다.
피드포워드 신경망의 출력층은 풀고자 하는 문제의 해의 구성요소와 관계되어 있는데, 필기체 숫자 인식의 경우 출력층의 노드는 0부터 9까지 숫자에 매핑되는 10개의 노드로 구성된다.
피드포워드 신경망에서 원하는 결과를 얻기 위해서는 각 노드를 잇는 링크가 갖는 값인 가중치(weight)를 적절한 값으로 조정해야 하는데 이것을 학습(learning)이라고 한다.
역전파(back propagation)는 라벨이 붙은 학습 데이터를 가지고 여러 개의 은닉층을 가지는 피드포워드 신경망을 학습시키는 데 사용되는 대표적 지도학습(supervised learning) 알고리즘이다. 역전파는 [그림 2-7]에서 볼 수 있듯이 두 단계로 구성되는데, 첫 번째 단계 에서는 학습 데이터를 신경망의 입력층에 전달하고 각 은닉층의 노드와 링크들을 거치며 계산된 값을 출력층 노드에서 출력한다. 두 번째 단계에서는 출력층의 출력 값과 라벨 값과의 오차를 최소화하도록 출력층부터 역방향으로 오차제곱합(sum squared error)의 경사 도(gradient) 정보를 이용하여 가중치를 조정한다.

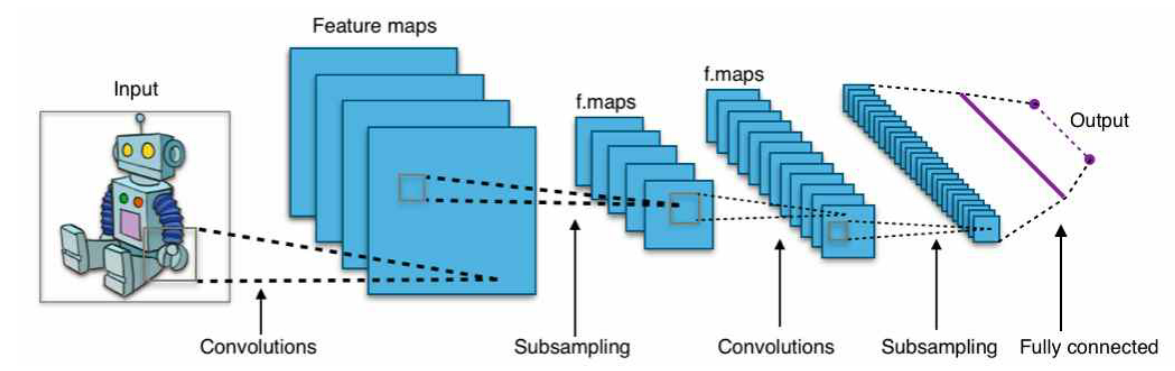
딥러닝(deep learning)의 한 분야로 영상인식에 많이 사용되고 있는 컨벌루션 신경망 (convolutional neural network)의 핵심기술들을 알아보면 다음과 같다.
• 사람의 시각인지 과정을 모방한 컨벌루션(convolution) 기법을 이용한 필터 커널(kennel) 사용 • 컨벌루션이 완료되면 각 픽셀에 있는 데이터를 활성화 함수에 적용해 판별력 강화. 활성화 함수로 ReLU(rectified linear unit) 함수가 많이 사용됨 • 처리할 데이터를 줄이기 위해 이웃한 데이터 간 대비율(contrast)을 높이고 데이터 수를 줄이는 풀링(pooling) 또는 서브샘플링(sub-sampling) 시행. 풀링에는 최대 풀링(max pooling), 평균 풀링(average pooling), 확률적 풀링(stochastic pooling)이 있음 • 상기 필터링 - 활성화 - 풀링 과정을 반복적으로 거치면서 좀 더 확대된 형체의 이미지 구성 • 마지막 풀링이 끝나면 데이터가 1차원 벡터 형태로 정렬되고 이 값들은 전체 연결 신경 망(fully-connected network)의 입력층으로 보내짐. 이후에는 몇 개의 추가적인 다층 신경망을 통해 피드포워드 및 역전파 과정을 거치며 학습이 진행됨
[그림 2-8]은 상기 과정을 통해 CNN이 입력 영상을 학습하는 과정을 보인다.
2012년 ImageNet의 영상인식 경연대회에서 압도적인 물체 인식률(오류율 16.4%)로 우승 하며 AI기술의 혁신을 일으킨 제프리 힌튼(GEOFFREY HINTON) 교수 팀의 SuperVision이 사용한 신경망 모델은 7개의 은닉층, 65만 개의 뉴런과 6,000만개의 변수, 6억 3,000만 개의 네트워크 연결로 구성되어 있다. 최근 이미지 인식 연구에서 마이크로소프트의 연구팀이 만든 ResNet은 무려 150개의 은닉층을 사용해서 예측 정확도를 높일 정도로 DNN의 구조는 점점 복잡해지고 있다.
DNN이 로봇에 적용된 사례는 다음과 같다.
• 영상인식과 음성인식 • 실시간으로 여러 사람의 자세 추정 • 실시간 행동분석 • 임의 형상을 가진 물체의 픽-플레이스
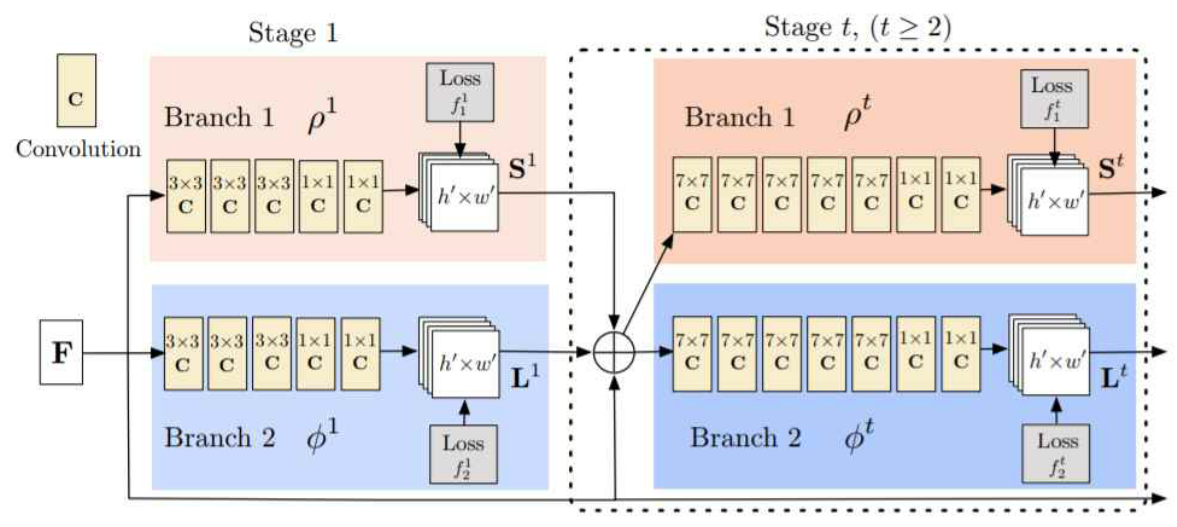
[그림 2-9]는 카네기멜론 대학교에서 openCV와 CNN을 기반으로 개발한 OpenPose가 동영 상으로부터 실시간 자세 추정을 하는 장면을 보이고, [그림 2-10]은 OpenPose의 CNN구조를 보인다.

3. 강화학습
강화학습(reinforcement learning)은 행동심리학의 강화(동물이 시행착오를 통해 학습하는 방법)를 인공지능에 접목한 알고리즘으로서 환경에 대한 사전지식이 없어도 환경과 상호 작용하면서 학습할 수 있다. 스키너(SKINNER)의 실험에서, 굶긴 쥐가 상자를 돌아다니다가 우연히 지렛대를 밟았는데 먹이가 나오고(보상) 이 과정이 몇 번 반복되면 쥐는 먹이와 지렛대 사이의 관계를 학습하게 되는데 이 과정이 바로 강화(reinforcement)이다.
강화학습은 에이전트와 환경으로 구성되는데, 에이전트는 강화학습을 통해 스스로 학습하는 주체를 의미하며, 환경은 에이전트에게 보상을 주고 다음 상태를 알려준다.
보상은 양수로 설정하면 상이고 음수로 설정하면 처벌이 된다. 에이전트는 적절한 상벌을
통해 무엇을 해야 하는지 더 명확하게 알 수 있다.
순차적으로 행동을 결정하는 강화학습 문제를 정의할 때 사용하는 방법인 MDP(markov decision process)은 상태, 행동, 보상함수, 감가율, 정책으로 구성된다.
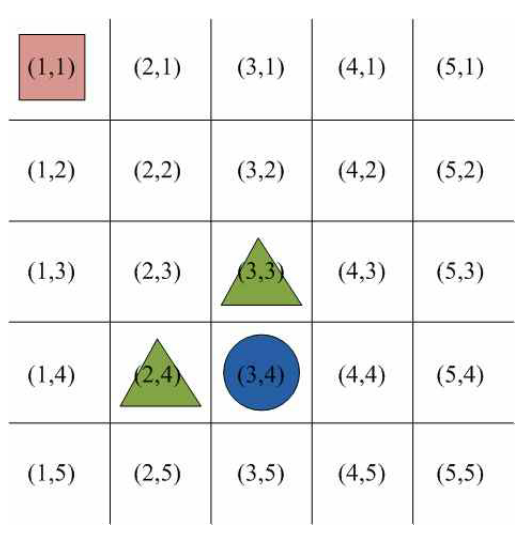
- 상태(state): 에이전트의 상황에 대한 관찰 값. [그림 2-11]에 보인 그리드 월드(grid world)의 상태 집합은 식 (2)와 같음. 예를 들어 시간 $t$에 에이전트가 (1,3)에 있으면 $S_{t} = (1,3)$으로 표현함
$S = \left \{ (1,1),(1,2),(1,3),\cdots, (5,5)\right \} \hspace{20em} (2)$
(1) 행동(action)
에이전트가 상태 에서 할 수 있는 가능한 행동의 집합. 그리드 월드의 행동 집합은식 (3)과 같음. 시간 에 에이전트가 오른쪽으로 이동하면 로 표현함
(2) 보상함수(reward function)
환경이 에이전트에게 주는 정보. 식 (4)는 시간 일 때 에이전트의 상태가 이고 행동이 일 때 에이전트가 받을 보상값이며, E는 기대값(expectation)을 의미함.
에이전트는 다음 시간인 에 환경으로부터 보상값 을 받는 것에 주의해야 함.
[그림 2-11]의 그리드 월드에서는 사각형으로 표현된 에이전트가 원이 있는 상태로 가는 행동을 했을 때는 의 보상을, 삼각형이 있는 상태로 가는 행동을 했을 때는 의 보상을 받음
(3) 감가율(discount factor)
나중에 받게 될 보상일수록 현재보다 가치가 줄어드는 것을 반영하기 위한 계수. 감가 율은 0과 1 사이의 값인 로 표기하며, 은 현재로부터 시간이 만큼 지난 후에 받는 보상값 를 현재 시점에서 계산한 값임
(4) 정책(policy)
모든 상태에서 에이전트가 할 행동의 집합이며, 상태가 입력으로 들어오면 행동을 출력으로 보내는 일종의 함수. 에이전트는 강화학습을 통해 최적 정책을 학습해야 함.
식 (5)는 시간 에 에이전트의 상태가 일 때 가능한 행동 중에서 를 할확률을 의미함
(5) 가치함수(value function)
어떠한 상태에 있으면 앞으로 얼마의 보상을 받을 것인지에 대한 기댓값. 식 (6)은 정책을 고려한 가치함수로서 현재 상태의 가치함수와 다음 상태의 가치함수 간의 관계를 알려주는 벨만 기대방정식(Bellman expectation equation)이다.
(6) 큐함수(Q function)
어떤 상태에서 어떤 행동이 얼마나 좋은지 알려주는 함수이며 에이전트가 정책을 업데이트할 때 많이 사용함. 큐함수는 상태, 행동이라는 두 가지 변수를 가지며 식 (7)에서 보듯이 가치함수의 조건문에 행동이 추가된다는 것이 다르다.
(7) 벨만 최적 방정식
에이전트가 최적의 정책을 따라갔을 때 받은 보상의 합
4. 최적화 알고리즘
최적화 알고리즘(optimization method)은 최소화해야 할 비용 함수(cost function)의 해를 수학적 방법이 아닌 컴퓨터 알고리즘으로 탐색하는 방법으로, 컴퓨터 CPU 연산 속도의 비약적인 향상과 효율적인 탐색 알고리즘의 발전으로 로봇의 지능 소프트웨어에 점점 더많이 적용되고 있다. 본 학습 모듈에서는 대표적 전역 최적화 알고리즘 중 코드 길이가 가장 짧으면서도 우수한 전역해 탐색 성능을 보이는 PSO를 사용한다.
(1) PSO(particle swarm optimization)
PSO는 KENNEDY와 EBERHART가 1995년 제안한 전역 최적화 알고리즘으로서 조류나 어류의 무리가 서로의 정보를 공유하면서 가장 먹이가 많은 곳을 찾아가는 과정을 컴퓨터 코드로 구현한 것이다.
PSO의 탐색 원리를 간단히 설명하면, 탐색변수가 개이고 총 개체 수가 인 한 집단 에서 번째 반복(iteration)차수의 탐색 시 ⋯ 번째 개체의 위치벡터를
∈ 이라고 하면, 그 개체는 지금껏 탐색했던 위치벡터 중 가장 우수한(비용함수를 최소화하는) 벡터를
값으로 저장한다. 또 매 반복차수에서 전체 개체의 위치를 업데이트 한 후 가장 좋은 해의 위치벡터를 라고 하면, PSO는 그 다음 업데이트 차수에서 번째 개체의 방향벡터
와 위치벡터
를 다음 식에 의해 결정한다.
식9
식10
식에서
와
는 현재 번째 개체의 방향벡터와 위치벡터를 각각 나타내며, 위치벡터에 방향벡터를 더함으로써 다음 차수의 위치벡터를 결정한다. 식에서 는 방향 벡터의 관성 가중치(inertial weight)를, 과 는 학습요인(learning factor)의 가중치 계수를 나타내며, 과 는 주변점을 랜덤하게 탐색하기 위해 0과 1 사이에서 발생시킨 균일분포난수(uniformly distributed random number)를 의미한다. [그림 2-12]는 2차원 탐색 공간에서 PSO의 번째 개체에서 식 (9)와 식 (10)을 이용하여 다음 위치벡터를 결정하는 원리를 벡터도로 표현한 것이다.

'Robotics : 로봇공학 > Certificate : 자격증' 카테고리의 다른 글
| 1-1-2 EtherCAT (0) | 2023.07.09 |
|---|---|
| 1-1-1 마이크로컨트롤러의 통신 방식 (0) | 2023.07.09 |
| Manipulator Force Cotnrol : 5-1-2-3 매니풀레이터 힘 제어 (0) | 2023.07.09 |
| 로봇 소프트웨어 구조설계 - 2. 로봇 시스템 통합 (0) | 2023.07.02 |
| "Engineer Robotics Software Development" Certification Study Note : "로봇소프트웨어개발기사" 출제 과목 노트 정리 (0) | 2023.07.01 |


